What Exactly Is a Token?—A Plain‑English Guide for LLM Beginners
If you've ever interacted with a large language model (LLM) like ChatGPT or used an AI-driven tool, you've probably heard the term "token" thrown around quite a bit. But what exactly is a token, and why does it matter? Let's break this down in easy-to-understand terms.
Tokens Defined: Simple Terms
In the context of LLMs, a token can be thought of as a piece or chunk of text—often smaller than a word but sometimes exactly a word. Tokens are how LLMs like GPT-4, Claude, and Gemini break down and process text.
Why Use Tokens Instead of Words?
Languages can be complicated. Some words are long, some words appear frequently, and some words are extremely rare. Breaking down text into tokens rather than using entire words helps the AI understand and generate language more efficiently.
For instance:
- Common words like "the" or "is" are typically a single token.
- Less common or longer words might be split into multiple tokens. For example, "tokenization" might become "token" and "ization."
Did You Know?
Different AI models use different tokenization methods, which means the same text might be split into different tokens depending on which model you're using. This is why token counts can vary between models!
How Tokens Are Created: Byte-Pair Encoding (BPE)
Most modern AI models like GPT-4 use something called Byte-Pair Encoding (BPE). This method first breaks text into individual characters and then progressively merges them into larger tokens based on how frequently certain pairs appear.
Think of it as the AI building its own custom vocabulary, optimized specifically for handling massive amounts of text.
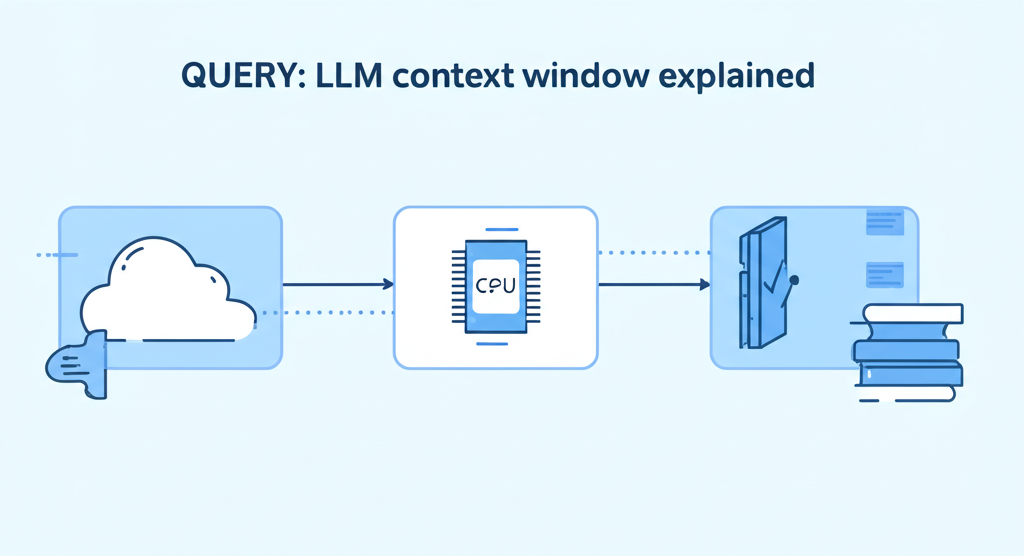
Why Do Tokens Matter?
Tokens are essential because LLMs have limits called "context windows." A context window defines how many tokens the AI can handle at once. GPT-4, for instance, can process up to 128,000 tokens in its context window. Understanding tokens helps users:
- Manage costs (AI services often bill based on token usage).
- Keep prompts within the AI's processing limits.
- Optimize prompts for better results.
Practical Example: Counting Tokens
Consider the sentence: "Hello, how are you?"
- "Hello" → 1 token
- "," → 1 token
- "how" → 1 token
- "are" → 1 token
- "you" → 1 token
- "?" → 1 token
This simple sentence has 6 tokens. Longer sentences or paragraphs, especially those with complex vocabulary, can quickly accumulate tokens.
Token Count Comparison
English Text
"The quick brown fox jumps over the lazy dog."
≈ 9 tokens
Code Snippet
function hello() { return "world"; }
≈ 11 tokens
Real-Life Use Case: Why You Should Care
Imagine you're developing an application using an LLM API. Each prompt and response costs tokens. Knowing how many tokens your text uses can help predict costs and avoid surprise bills. Tools (like our own token calculator!) can quickly show token counts, helping you optimize content to stay within budget.
Wrapping Up
In simple terms, tokens are the foundational units of text that language models use to read, process, and generate language. Understanding tokens is the first step towards effectively using, managing, and optimizing large language models.