Context Windows Explained: Making the Most of Your Token Limit
Context windows are one of the most important concepts to understand when working with large language models. This guide explains what they are, why they matter, and how to maximize their effectiveness in your applications.
What Is a Context Window?
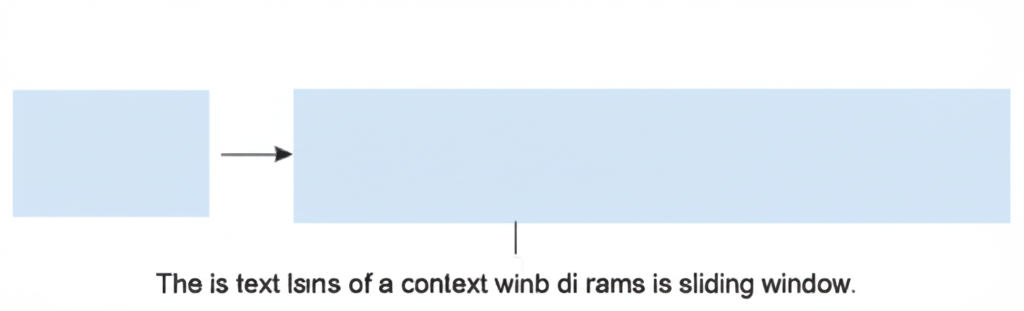
A context window is the amount of text (measured in tokens) that a language model can "see" and consider at any given time. It represents the model's working memory—all the information it can access when generating a response.
Think of it like a sliding window of text that moves through a conversation or document. The model can only "see" what's inside this window when generating its next output.
Context Window Sizes by Model
- GPT-4o: 128,000 tokens
- GPT-4 Turbo: 128,000 tokens
- Claude 3 Opus: 200,000 tokens
- Claude 3 Sonnet: 180,000 tokens
- GPT-3.5 Turbo: 16,000 tokens
- Gemini Pro: 32,000 tokens
Why Context Windows Matter
The size of a context window determines:
- How much information the model can consider at once
- How long conversations can be before earlier messages are forgotten
- How much documentation or reference material can be included
- The complexity of tasks the model can handle
Larger context windows enable more sophisticated applications, but they also come with higher costs and potential inefficiencies if not used properly.
Common Misconceptions
Misconception 1: The Model Remembers Everything
Many users assume that once they've told something to an LLM, it will remember it throughout the entire conversation. In reality, once information scrolls outside the context window, it's completely forgotten.
Misconception 2: Bigger Is Always Better
While larger context windows provide more capabilities, they also:
- Cost more (most providers charge per token)
- Can lead to "attention dilution" where the model struggles to focus on the most relevant information
- May increase latency for responses
Misconception 3: Context Windows Are Just for Conversations
Context windows aren't just for back-and-forth conversations. They're also crucial for:
- Document analysis and summarization
- Code generation with extensive references
- Complex reasoning tasks that require multiple steps
- Retrieval-augmented generation (RAG) applications
Context Window Visualization
Context window breakdown:
- • System prompt: 150 tokens
- • Conversation history: 4,850 tokens
- • Current user query: 1,000 tokens
- • Retrieved documents: 6,000 tokens
Strategies for Optimizing Context Window Usage
1. Summarize Conversation History
Instead of keeping the entire conversation history in the context window, periodically summarize previous exchanges. This technique is sometimes called "context compression."
❌ Inefficient
Keeping the entire conversation history of 20+ messages in the context window.
✅ Optimized
"Previous conversation summary: User asked about token optimization strategies. You provided 5 techniques including chunking and caching."
2. Use Retrieval-Augmented Generation (RAG)
Instead of loading entire documents into the context window, use RAG to:
- Store documents in a vector database
- Retrieve only the most relevant sections based on the current query
- Include only those sections in the context window
3. Implement Context Management
Develop a system to manage what goes into the context window:
- Prioritize recent and relevant information
- Remove redundant or outdated content
- Maintain a "memory" outside the context window that can be selectively included
// Pseudocode for context window management
function manageContextWindow(conversation, maxTokens = 8000) {
// Calculate current token usage
const currentTokenCount = countTokens(conversation);
if (currentTokenCount <= maxTokens) {
return conversation; // No management needed
}
// If we exceed the limit, compress older messages
const compressedHistory = summarizeOlderMessages(conversation);
// Keep the most recent messages intact
const recentMessages = getRecentMessages(conversation, 5);
return [...compressedHistory, ...recentMessages];
}4. Use Chunking for Long-Form Content
When working with long documents:
- Split the document into logical chunks (paragraphs, sections, etc.)
- Process each chunk separately
- Combine the results afterward
5. Be Strategic About System Prompts
System prompts consume tokens from your context window. Make them concise while still providing necessary instructions. Consider:
- Moving detailed examples to user messages where they can be removed later
- Using shorthand instructions that the model can understand
- Focusing on the most important guidelines
Measuring and Monitoring Context Usage
To effectively manage your context window:
- Track token usage for each component (system prompt, user messages, etc.)
- Set up alerts when approaching context limits
- Regularly audit your prompts for optimization opportunities
- Use a token counter (like ours!) to measure token usage before sending to the API
Need to measure your token usage?
Use our free token counter to see exactly how many tokens your text uses and how close you are to your context window limits.
Conclusion
Understanding and optimizing context windows is essential for building effective AI applications. By implementing the strategies outlined in this guide, you can:
- Maximize the capabilities of your chosen LLM
- Reduce costs by using tokens efficiently
- Build more sophisticated applications that handle complex tasks
- Provide better user experiences with faster, more relevant responses
As context windows continue to grow in size, the techniques for managing them will become increasingly important for developers working with AI.